Running AI On-device with a Lean, Performant Python Stack
Kunal Mohan

The introduction of Large Language Models (LLMs) and Generative AI (GenAI) has been a major milestone in the field of AI. With AI models encapsulating vast amounts of world knowledge, their ability to reason and understand human language has unlocked unprecedented possibilities. A wave of new assistance tools has swept through the digital industry, leveraging LLMs to enhance workflows, boost productivity, and deliver smarter, context-aware solutions. While enterprises have rapidly adopted GenAI to improve team efficiency, its integration into consumer applications remains limited. On one hand, GenAI has revolutionized the workflows of developers, marketers, content creators, and other professionals. On the other hand, the average everyday technology user remains largely unaffected by its introduction. We believe the main reason for this is that, in most current GenAI applications, users know they’re interacting with AI. This means the AI is given clear instructions or can easily figure out the user’s goal, and as a result, its use is mostly limited to professional settings. Whereas, to unlock the ultimate user experience on consumer applications, we must move past this “awareness” stage and have GenAI work intelligently and seamlessly for the user in the background, understanding their behaviour and intent in real time.
In a previous blog, we discussed this idea and saw how GenAI can transform the user experience like never before using its capabilities to understand the user intent based on their journey through the application so far. We introduced the concept of “Think before you recommend” and the three major abilities needed to achieve it. In this blog, we discuss the idea of on-device AI, the challenges that come with it, and how NimbleEdge’s on-device AI platform solves these challenges to build a scalable and privacy-aware AI platform to unleash the ultimate user experience on consumer applications.
The need to capture user intent in real-time requires AI pipelines to run at a scale of millions of users concurrently. Handling requests at such a large scale is a big challenge even for the leading state-of-the-art LLM providers, not to mention the high costs associated with it. Additionally, capturing user intent requires processing sensitive user data which enterprises may not be comfortable with sharing with a third party. For reference, this article by a16z predicts how processing of the large amounts of data produced by devices will grow beyond cloud capabilities and how the data processing and decision making will eventually shift to the edge.
The need for privacy aware AI, the challenges of cloud compute power to scale efficiently with the rate of data generation, and the increasing compute power of smartphones and other edge devices make a strong case for shifting towards on-device AI and compute. The idea of on-device AI is still in its infancy and unlike cloud, not a lot of tooling and frameworks are available to accomplish it. Any AI pipeline in the cloud today handles the following responsibilities:
Data collection and ingestion
Data storage
Data processing and feature computation
Model development and training
Model deployment and serving
Model monitoring and finetuning
While industry leaders like Microsoft, Meta, Google, and Apple have developed edge-specific runtimes such as ONNXRuntime, ExecuTorch, LiteRT, and CoreML, these tools focus solely on the model execution phase of the AI pipeline. This leaves the implementation of other essential components, such as data processing and feature computation, to application developers—a complex task, especially given the variability and diversity of user devices. Since the model development and training phases of an AI pipeline are confined to the cloud, maintaining consistency between devices and the cloud for data processing and feature computation is crucial to ensure coherence across model training and execution. To bridge this gap and simplify the development of AI applications across diverse environments, the NimbleEdge Platform provides a comprehensive on-device AI stack. This eliminates the complexity faced by developers and enables consistent and efficient AI workflows across a wide range of devices.
The NimbleEdge platform offers the following capabilities:
On-device event stream processing and optimized data ingestion
On-device data processing and feature computation
Global feature store synchronization to devices
Pipeline management and distribution
On-device model optimization and execution
Metrics collection for Model monitoring and finetuning
To learn more about on-device event stream processing and data ingestion aspect, check out these blogs.
Next, let’s look at the requirements and challenges with data processing and feature computation on user devices to better understand what NimbleEdge has to offer.
A number of tools and services (Eg: Databricks with Apache Spark, Apache Airflow, Apache Flink, AWS Glue, AWS Sagemaker, Snowflake, etc.) are available on the cloud for fast and efficient data processing. Depending on the rate of data generation and the liveness constraints on the model outputs, pipelines can be set up to process raw user data to extract useful features in real time or in a batched fashion to be fed into the models. The same is true for data storage where options are available from persistent storage solutions like AWS S3 to volatile storage like Redis. Depending on the nature of data and the latency constraints on querying the data, one or more storage solutions can be chosen.
The situation on user devices is quite different. Unlike the cloud, user devices have limited storage capacity. This makes managing user data efficiently on devices crucial. Storing too much data on-device can create bloat for the application’s data directories, raising red flags to the users. While the storage capacity of devices is increasing rapidly, the concerns are still valid as the amount of data generated follows suit. Ideally, only the latest data required for real-time user recommendations should be available on-device while the rest should be discarded or efficiently relayed to cloud for modelling, finetuning, or other intents.
Although libraries and frameworks for data processing exist on android and iOS, they often raise concerns regarding performance, memory consumption, and feature coverage when compared to the python libraries commonly used in the cloud environment. Additionally, using these libraries requires translating data processing logic and corresponding tests—originally written in Python—into frontend languages like Kotlin or Swift, which is a complex and error-prone task. Translating it for fast and efficient execution also requires learning and knowledge of the intricacies of the frontend language, which may not be easy. This process also increases the risk of bugs, as fixes necessitate application updates that depend on users updating their apps. Bugs in such critical components, if left unresolved, can lead to significant impacts. While force updates are a potential solution, they often leave a negative impression on users.
The AI pipelines running in the cloud are independent of the user app lifecycle. Even if the APIs may be locked-in with an app version, AI teams have complete control of training and deployment of models and updates to data processing and feature compute pipelines. There is almost always a backend interface that enables communication between the two, enabling independent updates for both AI pipelines and the user application.
Enabling AI on mobile applications by shipping models with the app and integrating data processing and feature computation code into the frontend introduces significant challenges to both AI pipeline deployment and application delivery. We’ve seen that beyond the technical hurdles, this approach creates several organizational bottlenecks. It necessitates direct collaboration between the AI and frontend teams—a dynamic that, in our experience, is often absent in many organizations. Additionally, the priorities and constraints of these teams are frequently at odds, making consensus difficult to achieve. For instance, while the AI team may advocate for more data to be available on-device for real-time recommendations, the frontend team is typically focused on minimizing the application’s storage and memory footprint.
To tackle the challenges of enabling on-device AI, the NimbleEdge platform provides Edge Workflow Scripts and Event Store for AI teams to efficiently manage and process data on mobile applications. Edge workflow scripts enable AI teams to write data pre-processing, feature computation, model execution and post-processing logic in python, making it independent of the frontend application code. Event Store helps manage raw user interaction events on devices. Let’s take a deeper look at both the features.
Edge Workflow Scripts provide the following features for the AI teams to easily implement data processing and feature computation logic on devices:
Python syntax for ease of use for the AI teams.
Edge Workflow Scripts are written in Python, making them easy to write and understand—especially since Python is a widely accepted language in the AI community. Python also helps maintain coherence with AI pipelines that already exist in the cloud infrastructure. It eliminates the barrier of writing data processing and features computation logic in any new frontend language specifically for user devices, which may require learning and knowing the intricacies of the frontend language to implement the processing logic efficiently.
Frontend callable functions for model execution.
Functions defined in edge workflow scripts can be called from the application frontend code with the respective arguments using the NimbleEdge device SDKs. This lets AI engineers perform any preprocessing required to compute model inputs from the raw frontend input, run the actual model and perform any post-processing on the model outputs for the frontend to consume. This also unlocks the ability to chain multiple models within functions as well as across functions.
Access to global feature stores.
Model execution often needs some global application features along with real time user features. Edge Workflow Scripts let you access these global features on the devices and use them alongside the real time user features to compute all necessary inputs required for model execution. These global feature stores are synced from the cloud to devices within the defined liveness constraints by the NimbleEdge platform.
Access to dataframes and image processing functions for feature computation, and pre and post-processing of model inputs and outputs.
Our custom lightweight “nimbleedge” package provides pandas-like dataframe and regex support to structure and process data. AI engineers can simply import the package like any normal package in python and start using it. It enables them to perform on-device feature computation using the user events stored in the Event Store along with the global features synced to the devices. Various operations including filters, aggregations and joins are available for these purposes. New capabilities are being added to this package regularly, including efficient image processing operations.
Fine-grained data enrichment and filtering capabilities for relaying data to cloud for modelling and finetuning.
Edge Workflow Scripts provide the ability to define event hooks for operations to be performed on the user events being added to the Event Store and for events being relayed to the customer cloud. This helps them structure and filter data for feature computation and gives them more control over the data being collected in their cloud with the first layer of data validation and filtering happening on the device itself. More details about this are discussed in this blog.
Logging and metrics aggregation functions for monitoring.
Edge Workflow Scripts have built-in logging methods for the AI teams to monitor their feature computation and model execution results. These logs can be enabled on any or all devices and are ingested directly to the cloud.
Fast and efficient computations with small SDK size and memory footprint using an in-house cross-platform python runtime.
The Edge Workflow Scripts run on a lightweight and efficient home-grown cross-platform Python runtime keeping in mind low SDK size, resource consumption and memory footprint to avoid any impact to the user experience. It supports concurrent execution of Edge Workflow Script functions, incorporating built-in data safety features to ensure data integrity, even when executed simultaneously from different threads or coroutines. Moreover, due to the cross-platform nature of the runtime, the same script can be utilized across all types of user devices making it reliable and easier to manage when compared with device-specific data processing logic implementations.
OTA code updates independent of frontend application.
Edge Workflow Scripts can be updated on the user devices independent of the application using the NimbleEdge platform. We’ll share more on this in upcoming blogs.
The Event Store unlocks the ability to store and manage raw user events on-device for model execution or relaying them efficiently to the customer cloud. The user application can add data to the Event Store from the frontend application code using the NimbleEdge device SDKs. Based on the data expiry constraints defined in the Edge Workflow Scripts and the events relay filter defined on the NimbleEdge platform, only relevant events are stored on the device and relayed to the customers cloud efficiently.
Let’s look at an example to better understand the Event Store and the Edge Workflow Script. The following script describes how a food delivery application can track and utilize real time user click events on restaurants to make better recommendations to the user:
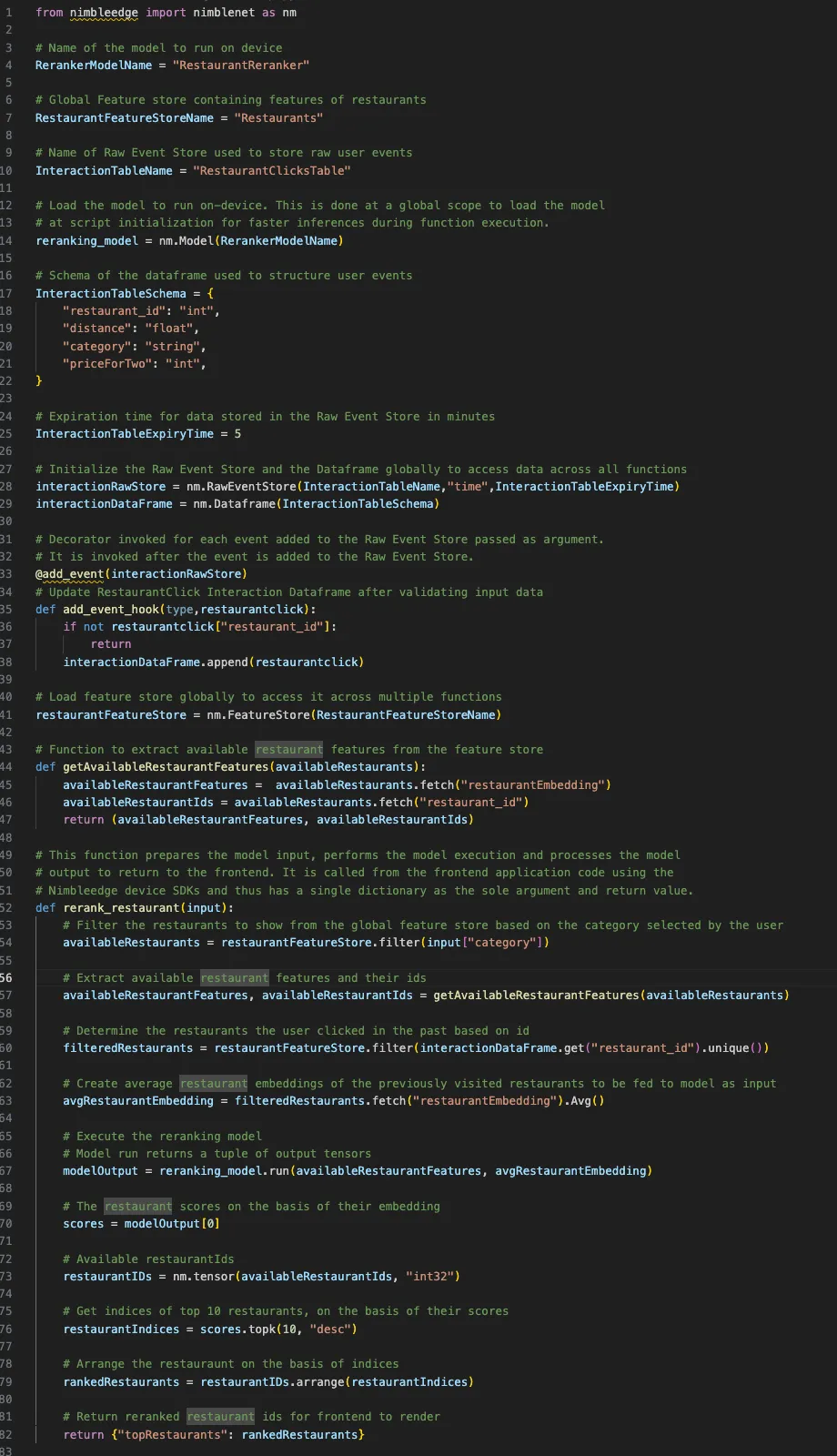
Here, the real-time user events from the last five minutes are stored in the “interactionRawStore” Event Store with validated, structured events present in “interactionDataframe” dataframe for operations and computations. The list of all restaurants to show are present in the “restaurantFeaturesStore” feature store. The “RestaurantReranker” model takes as input the list of available restaurants extracted from the feature store and the average restaurant embeddings of the restaurants clicked on by the user during the last five minutes. It outputs the restaurant scores which are used to reorder the restaurant IDs for the frontend to consume.
This is a very simple example, showcasing a small subset of the capabilities of the Edge Workflow Scripts. In real world scenarios, we believe that Edge Workflow Scripts can be a very powerful tool to implement and run very complex use cases in user applications. They will form the backbone for orchestrating on-device AI pipelines connecting all components including real-time user events, data processing and feature computation, global features accessibility, and model execution.
To learn more about on-device AI challenges and solutions, check out our blog and YouTube channel.

It is a valid question (isn’t it?) that why should we put effort into reducing the size of an SDK, with mobile storage capacities increasing all the time. Surely, how much do a few MBs matter when the device has multiple hundred gigabytes of sto

In our previous blog, we covered how NimbleEdge helps capture event streams

The Quiet Revolution: How Privacy, Efficiency and Decentralized Data are Reshaping AI's Future